This page contains details about Google Summer of Code project "Quantum GIS on steroids".
For a brief introduction of the project targets, check out my blog post on QGIS blog.
Important dates (see timeline):- May 24: summer of code begins
- July 12-16: mid-term evaluation
- August 16-20: final evaluation
Reports¶
| Week |
| Report |
| #01: 24.5. - 30.5. |
| [[#Week #01: May 24-30|report]] |
| #02: 31.5. - 6.6. |
| [[#Week #02: May 31 - June 6|report]] |
| #03: 7.6. - 13.6. |
| [[#Week #03: June 7-13|report]] |
| #04: 14.6. - 20.6. |
| [[#Week #04: June 14-20|report]] |
| #05: 21.6. - 27.6. |
| [[#Week #05: June 21-27|report]] |
| #06: 28.6. - 4.7. |
| [[#Week #06: June 28 - July 4|report]] |
| #07: 5.7. - 11.7. |
| [[#Week #07: July 5-11|report]] |
| #08: 12.7. - 18.7. |
| [[#Week #08: July 12-18|report]] |
| #09: 19.7. - 25.7. |
| [[#Week #09: July 19-25|report]] |
| #10: 26.7. - 1.8. |
| [[#Week #10: July 26 - August 1|report]] |
| #11: 2.8. - 8.8. |
| [[#Week 11: August 2-8|report]] |
| #12: 9.8. - 15.8. |
| [[#Week 12: August 9-15|report]] |
|
Final Report¶
The main contributions of this Google Summer of Code project:- map rendering is done in background and the user interface is not blocked during the rendering process, user can browse the map at any time - i.e. does not have to wait until the rendering is finished
- the map is continuously updated while rendering to give the user a clue what is happening
- map rendering uses all available CPUs to speed up rendering
- various speed improvements:
- fetching of vector data
- vector data drawing
- raster band statistics
- faster loading of attribute table
- changes visible for developers:
- refactored read access to vector data (using feature iterators)
- refactored vector editing routines
- reworked storing and passing of vector features
As I have expected, the start of the project went quite smoothly: modifying the rendering pipeline in QGIS
to use multiple threads was not very hard thanks to the QtConcurrent framework that has very convenient API.
The rendering work is split so that each map layer is one unit of work.
The framework is scales with the number of available CPUs: it spawns the number of threads equal to the
number of cores to make ideal use of the processing power. Thanks to this improvement, rendering of more layers
can be faster by the factor of number of CPUs in the machine. Though this is just a theoretical limit,
real tests show considerable speedup on a dual-core machine.
A more demanding task was to bring the rendering to the background, so that the main thread is not blocked.
This required several big modifications in the core libraries - with the requirement of keeping the API compatible.
This took several weeks and there are still some places which could get more testing and attention in regard
to locking. I'm quite happy with the result, because the target has been met: when rendering, the GUI stays
responsive (and the map is updated every 250 milliseconds). At any time the user can zoom or pan, the rendering
is canceled and rendering with new parameters start.
The second part of my project was dedicated mostly to finding and resolving bottlenecks in the rendering pipeline.
I have been profiling mostly Callgrind from Valgrind suite in conjunction with KCacheGrind to localize the places
that could be optimized. This combo proved to be useful and it allowed me to find out several issues. Btw. there is a very nice talk Optimizing Performance in Qt-Based Applications.
It's hard to estimate how much faster the rendering is in general. In some cases the performance has been improved
by factor 2x or even 3x, though there are cases which are slow and not much can be done to make it faster. Examples
include: antialiased rendering, bold lines, usage of SSL for connection to PostgreSQL or PNG/JPG for raster layers.
I have learnt various new things with regard to optimization and obtained more expertise in multithreaded programming.
The most interesting parts were designing multithreaded rendering (with its requirements) and finding out bottlenecks.
All in all, I consider this summer of code project as a success. All code has been contributed into SVN,
to a branch created for the GSoC project: http://svn.osgeo.org/qgis/branches/threading-branch/
The code still needs lots of testing until it can be considered as stable and integrated into mainline QGIS.
I would like to continue fixing and improving the code as my new job will allow.
Week 12: August 9-15¶
I have spent most of the time by polishing and finalizing various things, most notably:- finished OGR ignore fields patch: http://trac.osgeo.org/gdal/ticket/3716
- fixed WMS provider to work with threaded rendering
- faster rendering of complex polygons when zoomed in
- faster loading of attribute table
Week #11: August 2-8¶
I have spent this week implementing the previously suggested optimizations:
- use static arrays for rendering polylines and polygons
- implicit sharing of QgsFeature instances
- storing of attributes in a vector, not a map (the list of fields of a provider must not contain any holes)
Most of the time I've been updating the providers to work efficiently with the improved QgsFeature class. Additionally I have further improved the startup speed of attribute table and improved the speed of generation of raster layer statistics (2x).
On the GDAL/OGR front, RFC 29: Set Ignored Fields has been accepted.
This year's summer of code is slowly reaching the finals, I will spend the last week with testing, polishing and bugfixing. I will prepare the patch implementing the mentioned RFC. I am not blocked on anything.
Week #10: July 26 - August 1¶
I think I'm basically done with profiling of the performance of vector data. I have done two types of benchmarks: 1. fetching and rendering vector geometries with single symbol renderer, 2. fetching all data (geometry+attributes) from vector layers. The first is the typical use case for rendering, the second one when loading attribute table or doing batch processing.
A number of possible optimizations have shown up. For rendering:
- use static array of points instead of dynamic vector (QPointF* instead of QPolygonF)
- allow using fixed point precision (QPoint* instead of QPointF*)
- QgsFeature should use for attributes a vector, not a map
- QgsFeature should use implicit sharing
- providers should use list of fields instead of map of fields
- "system" text codec should be avoided by default as it does two conversions each time (at least when using iconv)
With experimental implementation of the suggested optimizations, the rendering time of testing shapefile went from 260ms to 200ms. Fetching of all data went from 1360ms to 815ms with PostGIS provider, from 1365ms to 510ms for OGR provider (involving also optimizations within OGR shapefile driver).
Next week I'd like to implement properly most of the mentioned suggestions.
Currently I am not blocked on anything.
Week #09: July 19-25¶
I have continued with profiling of the vector rendering pipeline. The tests were done in conjunction with OGR and PostGIS providers, these are (IMHO) the most important and used ones. I have identified some places where the performance could be improved, though this needs some more testing to see whether the proposed solutions will work.
From the last week's improvements for OGR, I've ended up writing an RFC: Set Desired Fields. It has been discussed on gdal-dev list and some suggestions were made.
Next week I am going to continue with profiling and start committing things that helps the data retrieval and rendering speed. I will also continue with the RFC work to get it approved and implemented. I am not blocked on anything.
Week #08: July 12-18¶
This week I have managed to finish the big refactoring of editing functionality of vector layer into a separate class. The implementation of locking of the editing buffer should be now straightforward.
I have adapted grass vector provider to new read API using iterator pattern, so now all providers support it. That also allowed me to shift the implementation of old API (which is emulated with new API) from provider implementations to base provider class.
In the gui area, I have implemented smart refreshing of map canvas: multiple refresh calls boil down to only one redraw which is started once the application enters event loop, thus it is more efficient.
Finally, I have started with some profiling (using benchmarks and callgrind) and I have done some optimizations. OGR library was a first target. With some tweaks of the shapefile driver, I was able to retrieve data about 3-4 times faster, resulting in roughly 2x faster rendering of shapefiles! More details in my post to gdal-dev. Hopefully the suggestions will be accepted in some form.
Next week I'm going to focus on further profiling, improvements and optimizations here and there. I'm not blocked on anything.
Week #07: July 5-11¶
I have continued mainly with the transition of the vector data providers to the new data read API as outlined last week. I have migrated all the remaining providers except GRASS provider: gpx, delimitedtext, memory, spatialite, wfs and osm. All of them currently use locking with mutexes to avoid run conditions from simultaneous reads. Modifying them to support concurrent read access without locking would grow the scope too much and it would shift us from the original targets.
I have realized that for safety it will be necessary to disable the old read API calls (select, nextFeature) during the threaded rendering: there is a scenario where a deadlock can be achieved if the main thread starts iterating the data and doesn't complete the iterating. The provider stays locked and the rendering threads waits infinitely. But temporary disabling the old API is not a big deal anyway: in v2.0 it can be expected that old API will be removed.
Other part of my work in previous week was refactoring of QgsVectorLayer class: a big part of its code relates to handling of the temporary editing buffer containing added, removed and modified features. To make the access to the vector layer in editing mode thread-safe, only one thread can be allowed to write to the buffer. That's the reason of the refactoring: to move all the code related to editing to a utility class, so it will be easier to overlook the locking of the buffer and the code of QgsVectorLayer gets a bit cleaner. This is a work in progress.
Next week I'd like to continue with the refactoring of the vector layer code and evaluate the most important missing bits in fully functional threaded rendering, so that we can concentrate on the second part of my task: speed optimizations. I am not being blocked by any particular issue.
Week #06: June 28 - July 4¶
I have concentrated on redesign and implementation of read access to features from vector layers. After having a working prototype, I've started a discussion on the qgis-dev mailing list regarding the new design. The design is based on iterator pattern and aims to keep backward compatibility with previous method. My first post is quite long, with both an introduction and some implementation details, so the interested reader can refer to it. Currently, I have reworked the read access using the new API for the two most important vector data providers (OGR and PostGIS) and for vector layers (which are in fact a combination of vector data provider and editing buffer). Both providers now use locking with mutexes to avoid concurrent access from multiple threads. In future they could be modified to handle concurrent accesses for even better user experience.
I've done also some digging into raster code: it doesn't allow to stop the rendering of raster while it's in progress and it doesn't show intermediate results. It turns out that the whole raster for the current window is first read by GDAL to a buffer, then prepared for rendering. The buffer can be made smaller to force multiple reads within GDAL and thus show intermediate results, but a simple solution I've tried as of now seems to kill the performance.
I'm still not blocked on anything in particular, though I would welcome more feedback on the new API for access to vector layers. My TODO list of pending tasks is ever growing, next week I'd like to convert the rest of the data providers to new API (7 more if I count correctly) if there are no objections and dig a little bit more into the raster code to see how the user feedback could be improved.
Week #05: June 21-27¶
I have been reviewing various parts of GUI code in order to make it working correctly. The most work is in main window, which contains a lot of actions that trigger rendering or access the map layers. The second main area is the code of the layer list (aka legend), which is centered around the management of layers and controls the map canvas widget.
During the review, I've fixed many issues concerning the threaded rendering and done some refactoring as a part of it. There are still many cases where the concurrency should be handled with care, so I expect this can take two more weeks to achieve stable performance.
I'm not really blocked on anything, I just have some doubts on how to implement the semantics for access to vector layers from threads. As noted before, this could be done by blocking the access to layer from main thread while rendering takes place (and vice versa: block rendering while layer is manipulated in main thread). Other possibility would be to redesign the API for access to vector layers to support multiple threads, however this will require quite some effort to maintain backward compatibility (which is essential as there are lots of plugins using it).
Week #04: June 14-20¶
There are not so many things to report about as the previous weeks. I have been sick for few days, unable to do any work.
I have fixed the support for render caching of vector layers. It is supposed to work as follows: when enabled, each layer is rendered to a separate image and the image is stored (cached). When a layer is going to be rendered again, the renderer first checks for existence of cached image and renders the layer again only if the cached image is not available, otherwise it just draws the image. Of course, this works only when the extent (and few other parameters) are unchanged. In general, this makes redrawing after various operations with layers much faster.
The current implementation of render caching had some problems, a serious limitation was that the cached image was stored within map layer. This could work with only one map renderer, but this is not usually the case - in QGIS there's one map renderer for map canvas, other for overview (and there could be more). It also complicates the threaded implementation, e.g. map renderer has no control of the cached images which can be invalidated at any time.
The new implementation introduces a new class QgsMapRendererCache which is internally used by each map renderer. When render caching is enabled, the class stores cached images for layers and the parameters of the view. Map renderer is connected to signals from layers that result into clearing the cached image of the layer, e.g. selection has changed. Also, threaded rendering has been updated to work with caching.
Next week I'd like to address further issues of threaded rendering - both within application GUI and locking in the core. I'm not blocked on anything.
Week #03: June 7-13¶
This week I've added functionality for asynchronous rendering within map renderer: when requesting asynchronous rendering, it is only scheduled and the control returns back to the calling (gui) thread. The rendering continues in background thread(s) and once it is finished, a signal is fired with resulting map. It is possible to retrieve the intermediate results or cancel the process while the rendering takes place.
Having this functionality in place, I've adapted map canvas widget to use the new asynchronous map rendering API. The result looks good: the user is able to continuously pan and zoom the map, without having to wait until the rendering is finished. Additionally, a timer called four times per second updates the image of the map while rendering on background to give the user a feedback. (Previously the incremental updates were done after rendering N features by emitting signals and manually entering the event loop to update the map, causing various problems.) In the combination of results from previous week, it can be seen (on multicore/-processor machines) that more layers are being rendered at once.
So, this looks like one of the main targets of this project has been met.
But we're still at the very beginning of the quest! The whole thing works only under "optimal" conditions. Most importantly, the code is vulnerable to run conditions and corruption of data (e.g. the user changes symbology of the layer being currently rendered). Second, the GUI is only half-functional while the rendering is running.
A lot of work has to be done to make sure that the threaded implementation is bulletproof: the rendering code must be reviewed and all variables used in rendering that can be modified must be handled. I see basically these directions:
- Clone the objects for rendering to avoid problems when they're being modified from the GUI thread - the worker threads using their local copy won't be affected. This could be probably applied only to small objects.
- Use synchronization primitives such as read/write locks and mutexes. This could affect the performance badly, since the locking is costly.
- Disable various operations while the rendering takes place - functions that modify the state of the objects used in rendering would simply ignore the requests. This would make the API very ugly as it would require checking whether the calls were successful... I don't like this approach.
Another source of problems I see is the way how iterating vector layer works: a select() call is issued first which tells the backend to prepare a set of features, which will be later retrieved with nextFeature() calls. A solution must be proposed to allow iterating layers from more threads at once or at least to guarantee that the calls are serialized.
Next week I'm going to dig into these problems and try to find ways out. I'm currently not blocked on anything. It would be great to have some documentation of good practices when converting API to be thread-safe, I haven't found anything comprehensive yet.
Week #02: May 31 - June 6¶
Good news from this week: I've managed to decouple the rendering process into smaller pieces of code. The code used for rendering map layers (in QgsMapRenderer class) has been made reentrant, that is it can be run from several threads at the same time without threads interfering between each other. If the threading is enabled, instead of directly rendering the map layers, only a list of jobs is created and then they are processed (rendered) in threads. Once the layers are all rendered into separate images, the images are blended together and the post-processing takes place (draw labeling and other stuff). Spawning of worker threads is done automatically within the QtConcurrent framework and is said to scale with the number of processors.
To test the performance on my dual-core machine, I've loaded a bunch of big shapefiles and let it run: cca 45 seconds without threading, cca 24 seconds with threading, so we are close to the 2x speed up under good conditions. Bad conditions would mean there is one hug layer (that takes a lot of time for processing) and zero or more small layers (that are rendered quickly) - such task cannot be split well and the speedup would be small (if any).
The rendering in threads can be used when rendering to raster images - for map canvas or other uses. I'm not sure if threading would be feasible for high-quality printing output (either raster or vector) - whether the memory footprint and extensive copying of rendered data would not decrease the multi-core performance gain. (I'm not going to investigate that now as I'm focusing on making the map browsing in map canvas faster and smoother).
For the next week, I'd like to get the threading code to a bit better shape, improve the caching of rendered map layers and start designing the necessary pieces to allow the whole rendering process to be run in a worker thread and the GUI won't be blocked in meanwhile.
Week #01: May 24-30¶
As I have announced before, this week was full of important school duties: on Monday 24 I had to defend my master thesis Structural Recognition of Facades (PDF) and then on Thursday 27 I was doing the final university exams. Fortunately I have been successful with both tasks.
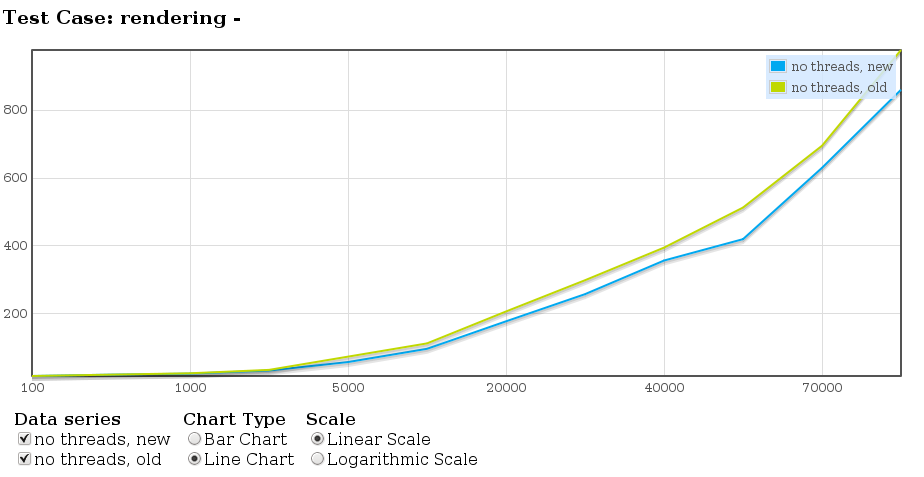
Regarding the SoC project, I've started to pick up the pace during the weekend: updated my QGIS copy, applied some patches and coded a benchmark to measure the rendering performance. Although the benchmarks are never perfect, they provide a good base when evaluating performance improvements.
I've started with evaluation of time for rendering a bunch of points. In the graph below, the number of points is on X axis, while time in milliseconds is on Y axis. The graph has been created with the help of qtestlib-tools. Here I've compared the new symbology (available from QGIS 1.4) to old symbology. The new implementation seems to perform about 10% better, however in other scenarios the performances may vary.